



















62 www.xilinx.com PowerPC™ 405 Processor Block Reference Guide
1-800-255-7778 UG018 (v2.0) August 20, 2004
Chapter 2: Input/Output Interfaces
R
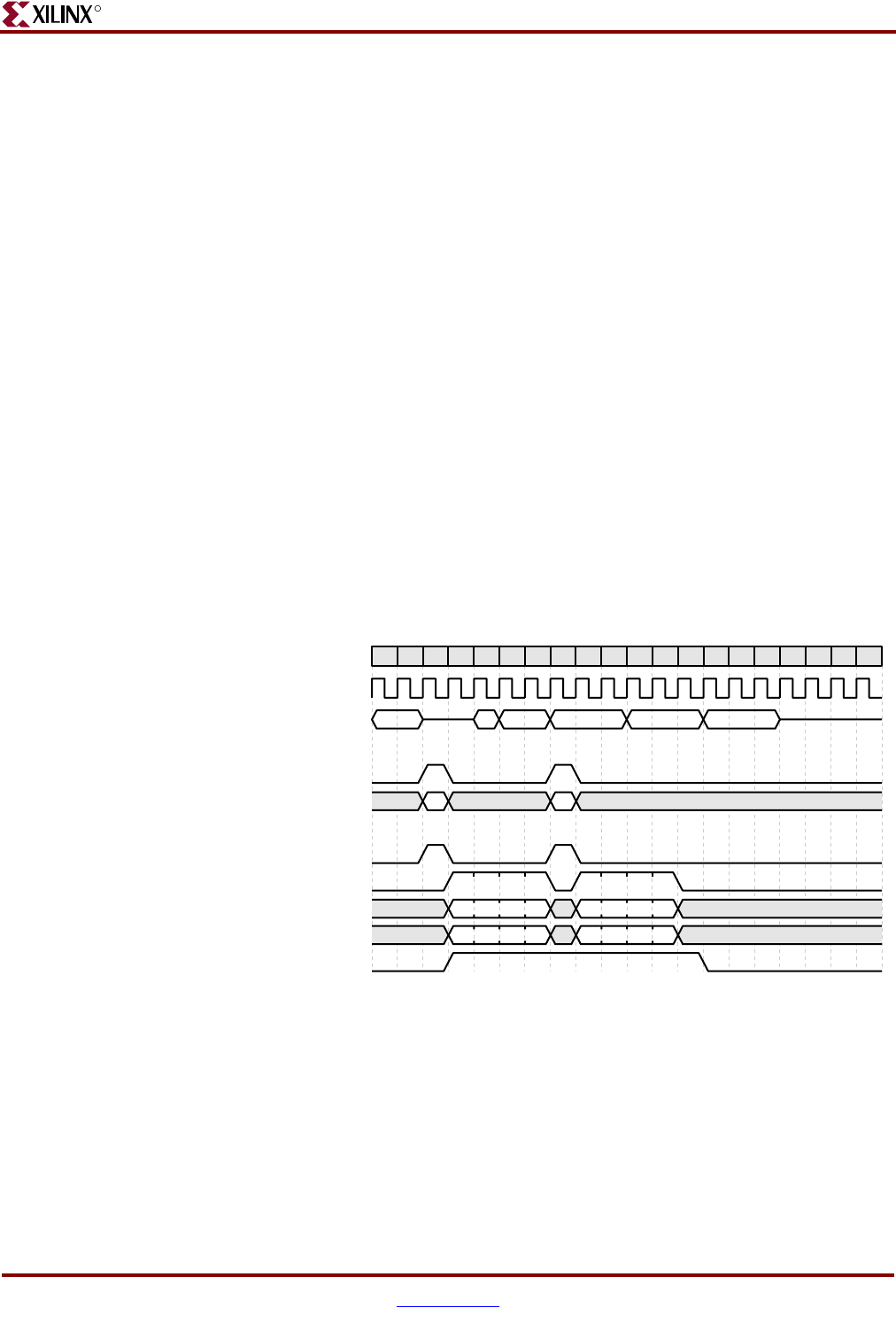
ISPLB Non-Pipelined Cacheable Sequential Fetch (Case 2)
The timing diagram in Figure 2-7 shows two consecutive eight-word line fetches that are
not address pipelined. The example assumes instructions are fetched sequentially from the
end of the first line through the end of the second line. It provides an illustration of a
transfer where the target instruction returned first by the BIU is not located at the start of
the cache line.
The first line read (rl1) is requested by the ICU in cycle 3 in response to a cache miss
(represented by the miss1 transaction in cycles 1 and 2). Instructions are sent from the BIU
to the ICU fill buffer in cycles 4 through 7. The target instruction is bypassed to the
instruction fetch unit in cycle 5 (byp1). After all instructions are received, they are
transferred by the ICU from the fill buffer to the instruction cache. This is represented by
the fill1 transaction in cycles 8 through 10.
After the target instruction is bypassed, a sequential fetch from the next cache line causes a
miss in cycle 6 (miss2). The second line read (rl2) is requested by the ICU in cycle 8 in
response to the cache miss. After the first line is read from the BIU, instructions for the
second line are sent from the BIU to the ICU fill buffer. This occurs in cycles 9 through 12.
Instructions in the fill buffer are bypassed to the instruction fetch unit to prevent a
processor stall during sequential execution (represented by the byp2 transaction in cycles
11 through 13). After all instructions are received, they are transferred by the ICU from the
fill buffer to the instruction cache (represented by the fill2 transaction in cycles 14 through
16).
ISPLB Pipelined Cacheable Sequential Fetch (Case 1)
The timing diagram in Figure 2-8 shows two consecutive eight-word line fetches that are
address pipelined. The example assumes instructions are fetched sequentially from the
beginning of the first line through the end of the second line. It shows the fastest speed at
which the ICU can request and receive instructions over the PLB.
Figure 2-7: ISPLB Non-Pipelined Cacheable Sequential Fetch (Case 2)
Cy cle
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
PLBCLK and CPMC405CLK
UG018_12_101701
PPC405 Outputs:
C405PLBICUREQUEST
C405PLBICUABUS[0:29]
adr1 adr2
fill1 fill2byp1 byp2miss2miss1
ICU
rl2rl1
rl2rl1
PLB/BIU Outputs:
PLBC405ICUADDRACK
PLBC405ICURDDBUS[0:63]
PLBC405ICURDWDADDR[1:3]
PLBC405ICURDDACK
rl1
67
rl1
01
rl1
23
rl1
45
rl2
01
rl2
23
rl2
45
rl2
67
d1
67
d1
01
d1
23
d1
45
d2
01
d2
23
d2
45
d2
67
6024 0246
PLBC405ICUBUSY